PostgreSQL-慢sql查询优化过程-大SQL文件分割-大表分页提交update结果
本文关键词
大SQL文件分割,大表分页提交update结果、执行计划、主键、索引。
重要说明
本文涉及到的分析过程主要基于1.7本地环境,最终结果是否适用于线上环境,暂未验证。
1. 背景
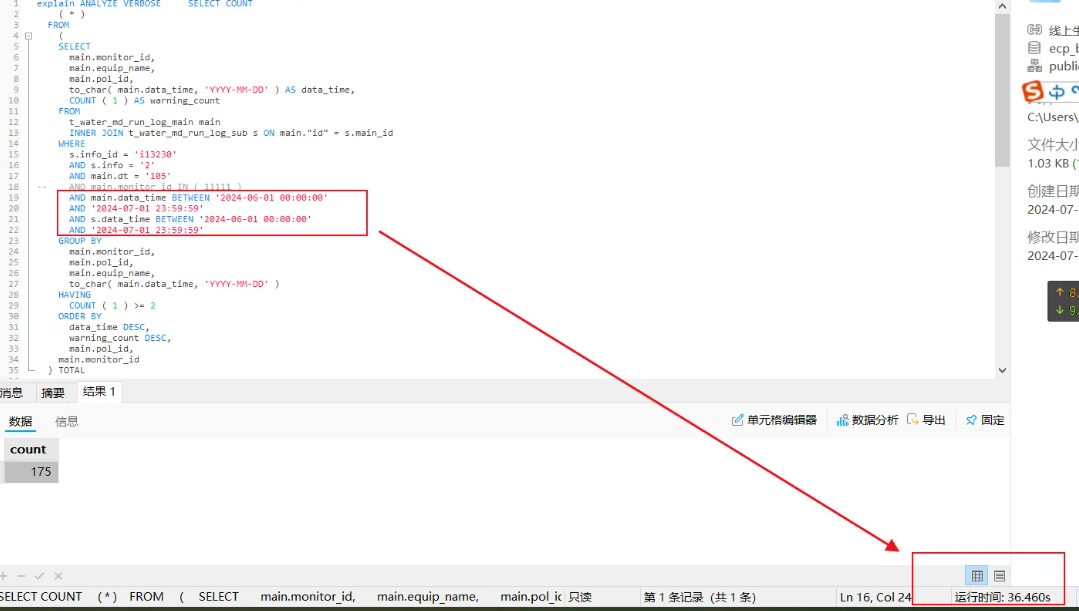
WHERE中的某些特定查询值在navicat中执行非常缓慢(在页面上调用接口今天未重现,返回比较快)
2. 整体说明
考虑到在线上环境操作表结构可能会影响用户使用,所以将线上数据同步到本地1.7数据库环境。
2.1. 同步数据到本地1.7数据库环境
通过navicat导出线上的t_water_md_run_log_main.sql、t_water_md_run_log_sub.sql非常大,分别有1.36G、4.44G。
将t_water_md_run_log_sub.sql本地环境导入到1.7数据库的过程中,非常缓慢,近2个小时,最终实时的处理进度也不太更新,整体无法导入。t_water_md_run_log_main.sql这个文件本身相对小,且导入前对文件做了一下修改保存,此表导入成功。
考虑要将t_water_md_run_log_sub.sql大文件分割成小文件,在网上未找到免费工具,所以通过Java代码来处理分割,相关代码和编码说明见 https://code.jiangjiesheng.cn/article/342。通过将大文件分割成3个小文件并再次尝试导入,实测导入成功。
2.2. 慢SQL
SELECT COUNT
( * )
FROM
(
SELECT
main.monitor_id,
main.equip_name,
main.pol_id,
to_char( main.data_time, 'YYYY-MM-DD' ) AS data_time,
COUNT ( 1 ) AS warning_count
FROM
t_water_md_run_log_main main
INNER JOIN t_water_md_run_log_sub s ON main."id" = s.main_id
WHERE
s.info_id = 'i13230'
AND s.info = '2'
AND main.dt = '105'
-- AND main.monitor_id IN ( 11111 )
AND main.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59'
AND s.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59'
GROUP BY
main.monitor_id,
main.pol_id,
main.equip_name,
to_char( main.data_time, 'YYYY-MM-DD' )
HAVING
COUNT ( 1 ) >= 2
ORDER BY
data_time DESC,
warning_count DESC,
main.pol_id,
main.monitor_id
) TOTAL在线上环境通过navicat执行上述SQL,需要37秒左右,在本地环境执行,也需要1.6秒左右
2.3. 线上环境执行计划
"Aggregate (cost=400.17..400.18 rows=1 width=8) (actual time=75638.849..75638.852 rows=1 loops=1)"
" Output: count(*)"
" -> Sort (cost=400.15..400.16 rows=1 width=83) (actual time=75638.816..75638.829 rows=175 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), (count(1))"
" Sort Key: (to_char(main.data_time, 'YYYY-MM-DD'::text)) DESC, (count(1)) DESC, main.pol_id, main.monitor_id"
" Sort Method: quicksort Memory: 49kB"
" -> GroupAggregate (cost=400.11..400.14 rows=1 width=83) (actual time=75637.021..75637.605 rows=175 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), count(1)"
" Group Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text))"
" Filter: (count(1) >= 2)"
" Rows Removed by Filter: 690"
" -> Sort (cost=400.11..400.11 rows=1 width=75) (actual time=75637.005..75637.090 rows=1133 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text))"
" Sort Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text)) DESC"
" Sort Method: quicksort Memory: 207kB"
" -> Nested Loop (cost=0.86..400.10 rows=1 width=75) (actual time=15.619..75628.505 rows=1133 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, to_char(main.data_time, 'YYYY-MM-DD'::text)"
" Join Filter: ((main.id)::text = (s.main_id)::text)"
" Rows Removed by Join Filter: 23272953"
" -> Index Scan using _t_water_md_run_log_sub_18426_chu_t_water_md_run_log_sub_infoid on _timescaledb_internal._t_water_md_run_log_sub_18426_chunk s (cost=0.43..147.71 rows=1 width=20) (actual time=1.582..7.072 rows=1133 loops=1)"
" Output: s.main_id"
" Index Cond: (((s.info_id)::text = 'i13230'::text) AND ((s.info)::text = '2'::text))"
" Filter: ((s.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (s.data_time <= '2024-07-01 23:59:59'::timestamp without time zone))"
" Rows Removed by Filter: 2303"
" -> Index Scan using _t_water_md_run_log_main_18425__t_water_md_run_log_main_data_ti on _timescaledb_internal._t_water_md_run_log_main_18425_chunk main (cost=0.43..249.45 rows=235 width=71) (actual time=0.114..63.455 rows=20542 loops=1133)"
" Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time, main.id"
" Index Cond: ((main.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (main.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((main.dt)::text = '105'::text))"
"Planning Time: 1.141 ms"
"Execution Time: 75638.902 ms""QUERY PLAN"
"Aggregate (cost=400.15..400.16 rows=1 width=8) (actual time=34283.887..34283.888 rows=1 loops=1)"
" Output: count(*)"
" -> GroupAggregate (cost=400.11..400.14 rows=1 width=83) (actual time=34283.539..34283.877 rows=175 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), NULL::bigint"
" Group Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text))"
" Filter: (count(1) >= 2)"
" Rows
by Filter: 690"
" -> Sort (cost=400.11..400.11 rows=1 width=75) (actual time=34283.528..34283.567 rows=1133 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text))"
" Sort Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text))"
" Sort Method: quicksort Memory: 207kB"
" -> Nested Loop (cost=0.86..400.10 rows=1 width=75) (actual time=58.503..34280.449 rows=1133 loops=1)"
" Output: main.monitor_id, main.equip_name, main.pol_id, to_char(main.data_time, 'YYYY-MM-DD'::text)"
" Join Filter: ((main.id)::text = (s.main_id)::text)"
" Rows Removed by Join Filter: 23272953"
" -> Index Scan using _t_water_md_run_log_sub_18426_chu_t_water_md_run_log_sub_infoid on _timescaledb_internal._t_water_md_run_log_sub_18426_chunk s (cost=0.43..147.71 rows=1 width=20) (actual time=2.085..4.981 rows=1133 loops=1)"
" Output: s.main_id"
" Index Cond: (((s.info_id)::text = 'i13230'::text) AND ((s.info)::text = '2'::text))"
" Filter: ((s.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (s.data_time <= '2024-07-01 23:59:59'::timestamp without time zone))"
" Rows Removed by Filter: 2303"
" -> Index Scan using _t_water_md_run_log_main_18425__t_water_md_run_log_main_data_ti on _timescaledb_internal._t_water_md_run_log_main_18425_chunk main (cost=0.43..249.45 rows=235 width=71) (actual time=0.061..28.805 rows=20542 loops=1133)"
" Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time, main.id"
" Index Cond: ((main.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (main.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((main.dt)::text = '105'::text))"
"Planning Time: 1.289 ms"
"Execution Time: 34283.931 ms" 2.4. 本地环境执行计划
Aggregate (cost=283615.39..283615.40 rows=1 width=8) (actual time=1247.733..1349.332 rows=1 loops=1)
Output: count(*)
-> Sort (cost=283615.37..283615.37 rows=1 width=82) (actual time=1247.686..1349.300 rows=175 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), (count(1))
Sort Key: (to_char(main.data_time, 'YYYY-MM-DD'::text)) DESC, (count(1)) DESC, main.pol_id, main.monitor_id
Sort Method: quicksort Memory: 49kB
-> Finalize GroupAggregate (cost=283614.92..283615.36 rows=1 width=82) (actual time=1245.217..1348.900 rows=175 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), count(1)
Group Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text))
Filter: (count(1) >= 2)
Rows Removed by Filter: 691
-> Gather Merge (cost=283614.92..283615.30 rows=3 width=82) (actual time=1245.176..1348.102 rows=1030 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), (PARTIAL count(1))
Workers Planned: 3
Workers Launched: 3
-> Partial GroupAggregate (cost=282614.88..282614.91 rows=1 width=82) (actual time=1226.984..1227.246 rows=258 loops=4)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), PARTIAL count(1)
Group Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text))
Worker 0: actual time=1221.558..1221.776 rows=219 loops=1
Worker 1: actual time=1221.618..1221.895 rows=266 loops=1
Worker 2: actual time=1222.114..1222.380 rows=249 loops=1
-> Sort (cost=282614.88..282614.88 rows=1 width=74) (actual time=1226.974..1227.001 rows=284 loops=4)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text))
Sort Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text)) DESC
Sort Method: quicksort Memory: 69kB
Worker 0: Sort Method: quicksort Memory: 58kB
Worker 1: Sort Method: quicksort Memory: 66kB
Worker 2: Sort Method: quicksort Memory: 64kB
Worker 0: actual time=1221.548..1221.571 rows=237 loops=1
Worker 1: actual time=1221.609..1221.636 rows=294 loops=1
Worker 2: actual time=1222.105..1222.131 rows=284 loops=1
-> Parallel Hash Join (cost=253063.76..282614.87 rows=1 width=74) (actual time=1196.893..1226.517 rows=284 loops=4)
Output: main.monitor_id, main.equip_name, main.pol_id, to_char(main.data_time, 'YYYY-MM-DD'::text)
Hash Cond: ((main.id)::text = (s.main_id)::text)
Worker 0: actual time=1191.423..1221.131 rows=237 loops=1
Worker 1: actual time=1191.683..1221.104 rows=294 loops=1
Worker 2: actual time=1192.017..1221.621 rows=284 loops=1
-> Parallel Index Scan using t_water_md_run_log_main_data_time_idx on public.t_water_md_run_log_main main (cost=0.43..29527.11 rows=6510 width=70) (actual time=0.335..27.962 rows=5141 loops=4)
Output: main.id, main.monitor_id, main.mn, main.data_time, main.dt, main.pol_id, main.type, main.mn_id, main.receive_time, main.polluter_name, main.monitor_name, main.equip_type_name, main.equip_name, main.data_time_day
Index Cond: ((main.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (main.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((main.dt)::text = '105'::text))
Worker 0: actual time=0.524..28.258 rows=4536 loops=1
Worker 1: actual time=0.316..28.064 rows=4605 loops=1
Worker 2: actual time=0.389..28.092 rows=4742 loops=1
-> Parallel Hash (cost=253063.24..253063.24 rows=7 width=20) (actual time=1195.371..1195.372 rows=284 loops=4)
Output: s.main_id
Buckets: 1024 Batches: 1 Memory Usage: 136kB
Worker 0: actual time=1190.653..1190.654 rows=295 loops=1
Worker 1: actual time=1190.656..1190.657 rows=276 loops=1
Worker 2: actual time=1191.133..1191.133 rows=255 loops=1
-> Parallel Seq Scan on public.t_water_md_run_log_sub s (cost=0.00..253063.24 rows=7 width=20) (actual time=959.834..1195.183 rows=284 loops=4)
Output: s.main_id
Filter: ((s.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (s.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((s.info_id)::text = 'i13230'::text) AND ((s.info)::text = '2'::text))
Rows Removed by Filter: 3917742
Worker 0: actual time=963.670..1190.456 rows=295 loops=1
Worker 1: actual time=951.701..1190.465 rows=276 loops=1
Worker 2: actual time=952.403..1190.954 rows=255 loops=1
Planning Time: 2.714 ms
Execution Time: 1349.576 ms3. 调试过程
3.1. 尝试对group by 字段建索引
CREATE INDEX "idx_group" ON "public"."t_water_md_run_log_main" USING btree (
"monitor_id" ,
"pol_id",
"equip_name" ,
"data_time"
);实测,执行效率没有改善
3.2. 尝试对order by字段建索引
CREATE INDEX "idx_order" ON "public"."t_water_md_run_log_main" (
"data_time",
"pol_id",
"monitor_id"
);实测,执行效率没有改善
3.3. 新建data_time_day字段保存来自data_time的年月日值
为了排除to_char函数对索引的影响。
ALTER TABLE "public"."t_water_md_run_log_main"
ADD COLUMN "data_time_day" DATE;
UPDATE t_water_md_run_log_main SET data_time_day = data_time::DATE;遇到问题,由于t_water_md_run_log_main表有474w条数据,上面的UPDATE SQL整体是一个超大事务,经过2个小时也无法完成提交。
尝试通过AI工具生成分页执行的SQL:
WITH batches AS (
SELECT id
FROM generate_series(1, (SELECT COUNT(*) FROM t_water_md_run_log_main)/10000) AS batch_num,
LATERAL (
SELECT id
FROM t_water_md_run_log_main
LIMIT 10000
OFFSET (batch_num - 1) * 10000
) AS subquery(id)
)
UPDATE t_water_md_run_log_main
SET data_time_day = data_time::date
WHERE EXISTS (SELECT 1 FROM batches WHERE batches.id = t_water_md_run_log_main.id);实测,上面的sql一样查询不动,修改10000为更小的值也查询不动。
感觉还是需要带有分页功能的SQL条提交:
UPDATE t_water_md_run_log_main SET data_time_day = data_time::date WHERE id in (SELECT id from t_water_md_run_log_main where data_time_day is null limit 50*10000 ) 修改具体分页大小测试执行效率:
20w 371秒,10w 181秒,5w 112秒,2.5w 43秒 1.25w 22秒
最终决定采用每次修改10w条。但是每次都需要人工执行,这样非常麻烦,所以需要借助类似for循环的PgSQL语法。通过AI工具生成并调试优化,最终如下:
3.3.1. 分页commit update数据SQL(关键SQL)
-- 30 x 100000 = 300 x 10w = 300w
DO $$
DECLARE
i integer;
BEGIN
FOR i IN 1..30 LOOP
RAISE NOTICE '执行第: % 次', i;
UPDATE t_water_md_run_log_main SET data_time_day = data_time::date WHERE id in (SELECT id from t_water_md_run_log_main where data_time_day is null limit 100000 ) ;
-- COMMIT非常关键,不然整个for循环就是1个大事务
-- COMMIT非常关键,不然整个for循环就是1个大事务
-- COMMIT非常关键,不然整个for循环就是1个大事务
COMMIT;
END LOOP;
END;
$$ LANGUAGE plpgsql;
查询时间: 4489.502s实时查询上述更新的数量(2条SQL均可使用):
SELECT * FROM
(
SELECT '未修改数量' AS "修改状态", COUNT (1), 1 AS orderNum FROM t_water_md_run_log_main WHERE data_time_day IS NULL UNION
SELECT '已修改数量' AS "修改状态", COUNT (1), 2 AS orderNum FROM t_water_md_run_log_main WHERE data_time_day IS NOT NULL
) T ORDER BY orderNum ASC;
SELECT COUNT (data_time_day IS NULL OR NULL) AS "未修改数量",COUNT (data_time_day IS NOT NULL OR NULL) AS "已修改数量" FROM t_water_md_run_log_main;3.4. 新data_time_day字段不建索引
实测,执行效率没有改善,首次执行需要71秒,第二次也是1.6秒
执行计划如下:
Aggregate (cost=283615.38..283615.39 rows=1 width=8) (actual time=1227.494..1314.633 rows=1 loops=1)
Output: count(*)
-> Sort (cost=283615.36..283615.37 rows=1 width=54) (actual time=1227.447..1314.600 rows=175 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time_day, (count(1))
Sort Key: main.data_time_day DESC, (count(1)) DESC, main.pol_id, main.monitor_id
Sort Method: quicksort Memory: 49kB
-> Finalize GroupAggregate (cost=283614.91..283615.35 rows=1 width=54) (actual time=1225.343..1314.390 rows=175 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time_day, count(1)
Group Key: main.monitor_id, main.pol_id, main.equip_name, main.data_time_day
Filter: (count(1) >= 2)
Rows Removed by Filter: 691
-> Gather Merge (cost=283614.91..283615.29 rows=3 width=54) (actual time=1225.319..1313.577 rows=1045 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time_day, (PARTIAL count(1))
Workers Planned: 3
Workers Launched: 3
-> Partial GroupAggregate (cost=282614.87..282614.90 rows=1 width=54) (actual time=1207.692..1207.949 rows=261 loops=4)
Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time_day, PARTIAL count(1)
Group Key: main.monitor_id, main.pol_id, main.equip_name, main.data_time_day
Worker 0: actual time=1202.589..1202.824 rows=232 loops=1
Worker 1: actual time=1202.551..1202.780 rows=240 loops=1
Worker 2: actual time=1202.774..1203.036 rows=279 loops=1
-> Sort (cost=282614.87..282614.88 rows=1 width=46) (actual time=1207.681..1207.708 rows=284 loops=4)
Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time_day
Sort Key: main.monitor_id, main.pol_id, main.equip_name, main.data_time_day DESC
Sort Method: quicksort Memory: 56kB
Worker 0: Sort Method: quicksort Memory: 49kB
Worker 1: Sort Method: quicksort Memory: 50kB
Worker 2: Sort Method: quicksort Memory: 54kB
Worker 0: actual time=1202.579..1202.603 rows=250 loops=1
Worker 1: actual time=1202.540..1202.565 rows=256 loops=1
Worker 2: actual time=1202.764..1202.793 rows=303 loops=1
-> Parallel Hash Join (cost=253063.76..282614.86 rows=1 width=46) (actual time=1178.562..1207.279 rows=284 loops=4)
Output: main.monitor_id, main.equip_name, main.pol_id, main.data_time_day
Hash Cond: ((main.id)::text = (s.main_id)::text)
Worker 0: actual time=1173.537..1202.192 rows=250 loops=1
Worker 1: actual time=1173.547..1202.144 rows=256 loops=1
Worker 2: actual time=1173.456..1202.300 rows=303 loops=1
-> Parallel Index Scan using t_water_md_run_log_main_data_time_idx on public.t_water_md_run_log_main main (cost=0.43..29527.11 rows=6510 width=66) (actual time=0.366..27.647 rows=5141 loops=4)
Output: main.id, main.monitor_id, main.mn, main.data_time, main.dt, main.pol_id, main.type, main.mn_id, main.receive_time, main.polluter_name, main.monitor_name, main.equip_type_name, main.equip_name, main.data_time_day
Index Cond: ((main.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (main.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((main.dt)::text = '105'::text))
Worker 0: actual time=0.467..27.903 rows=4419 loops=1
Worker 1: actual time=0.427..27.688 rows=4989 loops=1
Worker 2: actual time=0.458..27.753 rows=4653 loops=1
-> Parallel Hash (cost=253063.24..253063.24 rows=7 width=20) (actual time=1177.240..1177.241 rows=284 loops=4)
Output: s.main_id
Buckets: 1024 Batches: 1 Memory Usage: 136kB
Worker 0: actual time=1172.644..1172.645 rows=270 loops=1
Worker 1: actual time=1172.639..1172.640 rows=291 loops=1
Worker 2: actual time=1172.829..1172.830 rows=279 loops=1
-> Parallel Seq Scan on public.t_water_md_run_log_sub s (cost=0.00..253063.24 rows=7 width=20) (actual time=940.033..1177.052 rows=284 loops=4)
Output: s.main_id
Filter: ((s.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (s.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((s.info_id)::text = 'i13230'::text) AND ((s.info)::text = '2'::text))
Rows Removed by Filter: 3917742
Worker 0: actual time=943.010..1172.465 rows=270 loops=1
Worker 1: actual time=927.739..1172.444 rows=291 loops=1
Worker 2: actual time=943.202..1172.639 rows=279 loops=1
Planning Time: 2.619 ms
Execution Time: 1314.890 ms3.5. 尝试对data_time_day新字段建索引
CREATE INDEX "idx_new_field" ON "public"."t_water_md_run_log_main" (
"monitor_id",
"equip_name",
"pol_id",
"data_time_day"
);实测,执行效率没有改善
3.6. 关键开始->突破
SELECT
main.monitor_id,
main.equip_name,
main.pol_id,
main.data_time_day AS data_time
FROM
t_water_md_run_log_main main
INNER JOIN t_water_md_run_log_sub s ON main.id = s.main_id
WHERE
s.info_id = 'i13230'
AND s.info = '2'
AND main.dt = '105'
-- AND main.monitor_id IN ( 11111 )
AND main.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59'
AND s.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59' 通过分析代码和表结构,发现缺少join on 条件: and main.monitor_id=s.monitor_id (关键1/3)
在线上环境添加on条件后,执行时间从36秒降低到19秒。
另外发现t_water_md_run_log_main表缺少id主键设置,结合where条件,一次性添加相关的主键和索引:
DROP INDEX "public"."idx_group";
DROP INDEX "public"."idx_new_field";
DROP INDEX "public"."idx_order";
ALTER TABLE "public"."t_water_md_run_log_main" -- 关键2/3
ADD PRIMARY KEY ("id");
CREATE INDEX "idx_where" ON "public"."t_water_md_run_log_main" (
"dt",
"monitor_id",
"data_time"
);
-- PgSQL的索引名应是模式内唯一
CREATE INDEX "idx_t_water_md_run_log_sub_where" ON "public"."t_water_md_run_log_sub" USING btree ( -- 关键3/3
"info_id",
"info",
"data_time"
);
CREATE INDEX "idx_t_water_md_run_log_sub_join" ON "public"."t_water_md_run_log_sub" USING hash (
"main_id"
);
CREATE INDEX "idx_t_water_md_run_log_sub_join_where" ON "public"."t_water_md_run_log_sub" USING btree (
"main_id",
"info_id",
"info",
"data_time"
);再次执行SELECT、group by 、执行计划,消耗时间平均在0.5秒
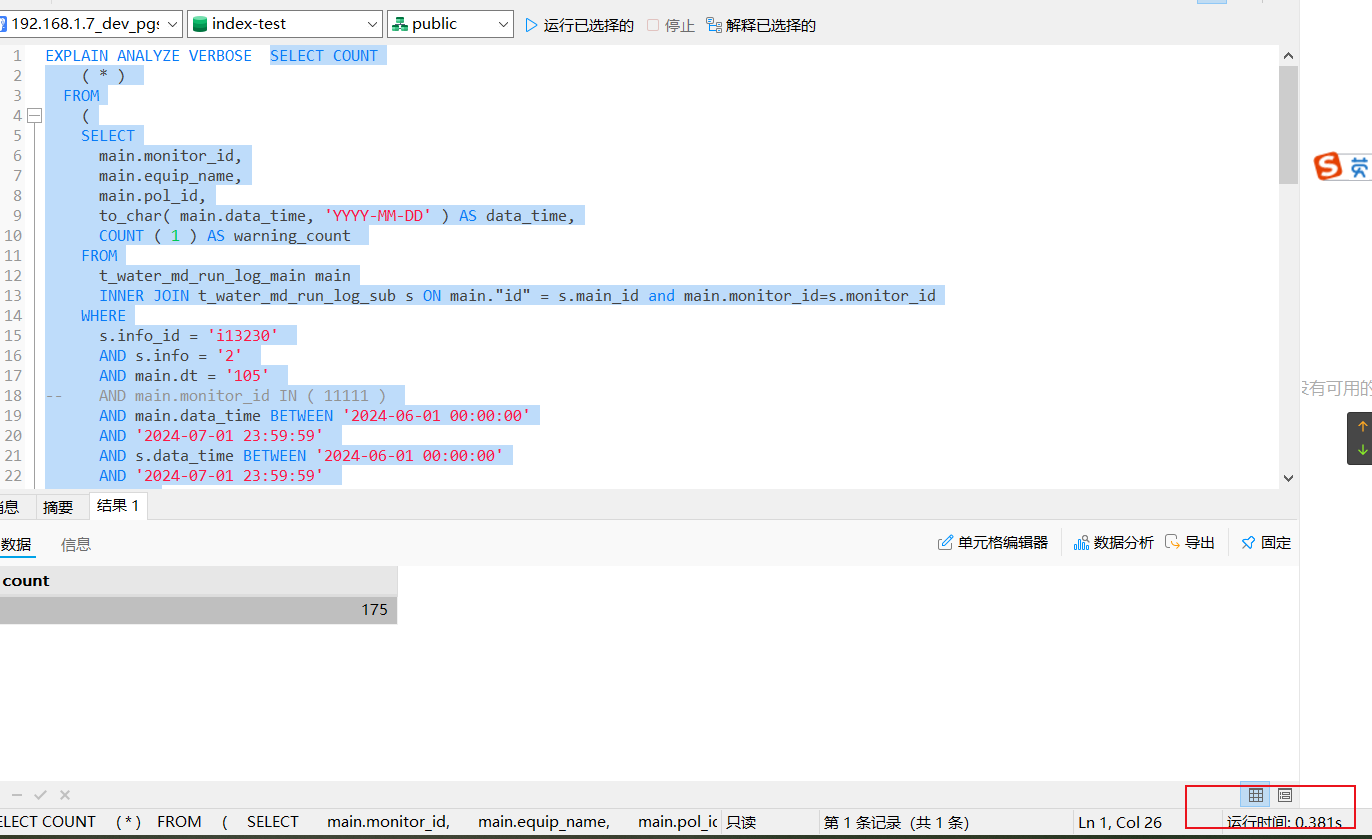
3.6.1. 最终SQL验证
EXPLAIN ANALYZE VERBOSE SELECT COUNT
( * )
FROM
(
SELECT
main.monitor_id,
main.equip_name,
main.pol_id,
to_char( main.data_time, 'YYYY-MM-DD' ) AS data_time,
COUNT ( 1 ) AS warning_count
FROM
t_water_md_run_log_main main
INNER JOIN t_water_md_run_log_sub s ON main."id" = s.main_id and main.monitor_id=s.monitor_id
WHERE
s.info_id = 'i13230'
AND s.info = '2'
AND main.dt = '105'
-- AND main.monitor_id IN ( 11111 )
AND main.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59'
AND s.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59'
GROUP BY
main.monitor_id,
main.pol_id,
main.equip_name,
to_char( main.data_time, 'YYYY-MM-DD' )
HAVING
COUNT ( 1 ) >= 2
ORDER BY
data_time DESC,
warning_count DESC,
main.pol_id,
main.monitor_id
) TOTAL;
SELECT
main.monitor_id,
main.equip_name,
main.pol_id,
to_char( main.data_time, 'YYYY-MM-DD' ) AS data_time
FROM
t_water_md_run_log_main main
INNER JOIN t_water_md_run_log_sub s ON main."id" = s.main_id and main.monitor_id=s.monitor_id
WHERE
s.info_id = 'i13230'
AND s.info = '2'
AND main.dt = '105'
-- AND main.monitor_id IN ( 11111 )
AND main.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59'
AND s.data_time BETWEEN '2024-06-01 00:00:00'
AND '2024-07-01 23:59:59';执行计划:
Aggregate (cost=133.87..133.88 rows=1 width=8) (actual time=23.879..23.880 rows=1 loops=1)
Output: count(*)
-> Sort (cost=133.85..133.86 rows=1 width=81) (actual time=23.833..23.850 rows=175 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), (count(1))
Sort Key: (to_char(main.data_time, 'YYYY-MM-DD'::text)) DESC, (count(1)) DESC, main.pol_id, main.monitor_id
Sort Method: quicksort Memory: 49kB
-> GroupAggregate (cost=133.81..133.84 rows=1 width=81) (actual time=22.532..23.454 rows=175 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text)), count(1)
Group Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text))
Filter: (count(1) >= 2)
Rows Removed by Filter: 691
-> Sort (cost=133.81..133.81 rows=1 width=73) (actual time=22.510..22.610 rows=1134 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, (to_char(main.data_time, 'YYYY-MM-DD'::text))
Sort Key: main.monitor_id, main.pol_id, main.equip_name, (to_char(main.data_time, 'YYYY-MM-DD'::text)) DESC
Sort Method: quicksort Memory: 207kB
-> Nested Loop (cost=0.99..133.80 rows=1 width=73) (actual time=0.122..20.240 rows=1134 loops=1)
Output: main.monitor_id, main.equip_name, main.pol_id, to_char(main.data_time, 'YYYY-MM-DD'::text)
Inner Unique: true
-> Index Scan using idx_t_water_md_run_log_sub_where on public.t_water_md_run_log_sub s (cost=0.56..40.34 rows=35 width=24) (actual time=0.054..2.615 rows=1134 loops=1)
Output: s.id, s.main_id, s.monitor_id, s.info_id, s.info, s.data_time
Index Cond: (((s.info_id)::text = 'i13230'::text) AND ((s.info)::text = '2'::text) AND (s.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (s.data_time <= '2024-07-01 23:59:59'::timestamp without time zone))
-> Index Scan using t_water_md_run_log_main_pkey on public.t_water_md_run_log_main main (cost=0.43..2.66 rows=1 width=69) (actual time=0.011..0.011 rows=1 loops=1134)
Output: main.id, main.monitor_id, main.mn, main.data_time, main.dt, main.pol_id, main.type, main.mn_id, main.receive_time, main.polluter_name, main.monitor_name, main.equip_type_name, main.equip_name, main.data_time_day
Index Cond: ((main.id)::text = (s.main_id)::text)
Filter: ((main.data_time >= '2024-06-01 00:00:00'::timestamp without time zone) AND (main.data_time <= '2024-07-01 23:59:59'::timestamp without time zone) AND ((main.dt)::text = '105'::text) AND (s.monitor_id = main.monitor_id))
Planning Time: 4.676 ms
Execution Time: 24.017 ms3.6.2. 结合执行计划,总结最终修改
INNER JOIN t_water_md_run_log_sub s ON main."id" = s.main_id and main.monitor_id=s.monitor_id
ALTER TABLE "public"."t_water_md_run_log_main"
ADD PRIMARY KEY ("id");
CREATE INDEX "idx_t_water_md_run_log_sub_where" ON "public"."t_water_md_run_log_sub" USING btree (
"info_id",
"info",
"data_time"
);
其他同时添加的索引可能也有作用,这里就不删除验证了。4. 附录
4.1. AI解读PgSQL中的单引号和双引号
单引号(' ')
单引号主要用于字符串字面量,即文本数据。当你需要在 SQL 查询中插入文本字符串时,你应该使用单引号将字符串包围起来。例如:
SELECT 'Hello, world!';
或者在插入数据时:
INSERT INTO my_table (name) VALUES ('John Doe');
双引号(" ")
双引号则有以下几种用途:
标识符引用:在 SQL 标准中,双引号被用来引用标识符(如表名、列名、函数名等),特别是当这些标识符是关键字或包含空格或特殊字符时。例如:
SELECT "My Column Name" FROM "My Table";
大小写敏感:在 PostgreSQL 中,使用双引号的标识符是大小写敏感的。例如,"MyColumn" 和 "mycolumn" 将被视为两个不同的列名。
保留字作为标识符:如果需要将 SQL 保留字用作标识符(如表名或列名),必须使用双引号。例如:
CREATE TABLE "select" ("from" int);
转义序列:双引号还用于包含转义序列,比如在字符串中插入另一个双引号,需要使用两个双引号。例如:
SELECT '"Hello, ""world""!""';
然而,值得注意的是,在 PL/pgSQL 中编写函数或过程时,字符串常量通常也使用单引号。在定义变量或进行字符串操作时,你同样应该使用单引号。
在编写 SQL 查询或 PL/pgSQL 代码时,确保正确使用单引号和双引号,以避免语法错误和意外的行为。



